45 class labels in data mining
Data Mining - Classification & Prediction - tutorialspoint.com The classifier is built from the training set made up of database tuples and their associated class labels. Each tuple that constitutes the training set is referred to as a category or class. These tuples can also be referred to as sample, object or data points. Using Classifier for Classification What is the difference between classes and labels in machine ... - Quora CLASS: It is the category or set where the data is "labelled" or "tagged" or "classified" to belong to a specific class based on their common property or attribute. Class label is the discrete attribute having finite values (dependent variable) whose value you want to predict based on the values of other attributes (features). LABEL:
What is a "class label" re: databases - Stack Overflow 2 The class label is usually the target variable in classification. Which makes it special from other categorial attributes. In particular, on your actual data it won't exist - it only exist on your training and validation data sets. Class labels often don't reliably exist for other data mining tasks. This is specific to classification. Share

Class labels in data mining
Data Mining - (Class|Category|Label) Target - Datacadamia Data-Science - Cheatsheet (Class|Category|Label) Target (Classifier|Classification Function) Clustering (Function|Model) Coin Flipping (Prediction|Recommender System) - Collaborative filtering Competitions (Kaggle and others) Confidence Interval Statistics - (Confidence|likelihood) (Prediction probabilities|Probability classification) Data mining algorithms: Classification - CCSU Step 1: Using a learning algorithm to extract rules from (create a model of) the training data. The training data are preclassified examples (class label is known for each example). Step 2: Evaluate the rules on test data. training sample (2/3) and test sample (1/3). Step 3: Apply the rules to (classify) new data (examples with unknown class Data Mining Techniques - GeeksforGeeks The determined model depends on the investigation of a set of training data information (i.e. data objects whose class label is known). The derived model may be represented in various forms, such as classification (if - then) rules, decision trees, and neural networks. Data Mining has a different type of classifier: Decision Tree
Class labels in data mining. Data mining - Class label field The class label field contains the class labels of the classes to which the records in the source data were attributed during the historical classification. Class label field ... Selected input fields for the Classification mining function; Input fields Class label field; Town districts: Risk class: Country: Profession: Related concepts. Machine learning - Wikipedia Machine learning and data mining often employ the same methods and overlap significantly, but while machine learning focuses on prediction, based on known properties learned from the training data, data mining focuses on the discovery of (previously) unknown properties in the data (this is the analysis step of knowledge discovery in databases ... Data-mining: Classification - theintactone Data-mining: Classification There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. These two forms are as follows: Classification Prediction Classification models predict categorical class labels; and prediction models predict continuous valued functions. Data mining — Specifying the class label field - IBM Class labels can include up to 256 characters. Use DM_setClasTarget to specify the class label field (target field) for a DM_ClasSettings value. The mining data type of this field must be categorical. The specification of this field is mandatory. In the following example, the logical data specification is created manually.
Decision tree learning - Wikipedia Decision trees used in data mining are of two main types: Classification tree analysis is when the predicted outcome is the class (discrete) to which the data belongs. Regression tree analysis is when the predicted outcome can be considered a real number (e.g. the price of a house, or a patient's length of stay in a hospital). Class labels in data partitions - Cross Validated Using a method like stratified sampling, you would make certain that each class is represented by randomly selecting instances of that class for each data set. If you are running into this problem, you also might question whether you have enough data to train your algorithm well. Support vector machine - Wikipedia where the are either 1 or −1, each indicating the class to which the point belongs. Each is a -dimensional real vector. We want to find the "maximum-margin hyperplane" that divides the group of points for which = from the group of points for which =, which is defined so that the distance between the hyperplane and the nearest point from either group is maximized. IDM Members Meeting Dates 2022 | Institute Of Infectious ... Feb 16, 2022 · IDM Members' meetings for 2022 will be held from 12h45 to 14h30.A zoom link or venue to be sent out before the time.. Wednesday 16 February; Wednesday 11 May; Wednesday 10 August
Data Mining - Decision Tree Induction - tutorialspoint.com Generating a decision tree form training tuples of data partition D Algorithm : Generate_decision_tree Input: Data partition, D, which is a set of training tuples and their associated class labels. attribute_list, the set of candidate attributes. Attribute selection method, a procedure to determine the splitting criterion that best partitions ... Classification in Data Mining Explained: Types, Classifiers ... Classification in data mining is a common technique that separates data points into different classes. It allows you to organize data sets of all sorts, including complex and large datasets as well as small and simple ones. It primarily involves using algorithms that you can easily modify to improve the data quality. Classification in Data Mining The two important steps of classification are: 1. Model construction. A predefine class label is assigned to every sample tuple or object. These tuples or subset data are known as training data set. The constructed model, which is based on training set is represented as classification rules, decision trees or mathematical formulae. Classification & Prediction in Data Mining - Trenovision predicts categorical class labels (discrete or nominal). classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data. Prediction models continuous-valued functions, i.e., predicts unknown or missing values. Supervised vs. Unsupervised Learning
Hierarchical multi-label classification using local neural ...
Various Methods In Classification - Data Mining 365 Classification is the data analysis method that can be used to extract models describing important data classes or to predict future data trends and patterns. (Read also -> Data Mining Primitive Tasks) Classification is a data mining technique that predicts categorical class labels while prediction models continuous-valued functions.
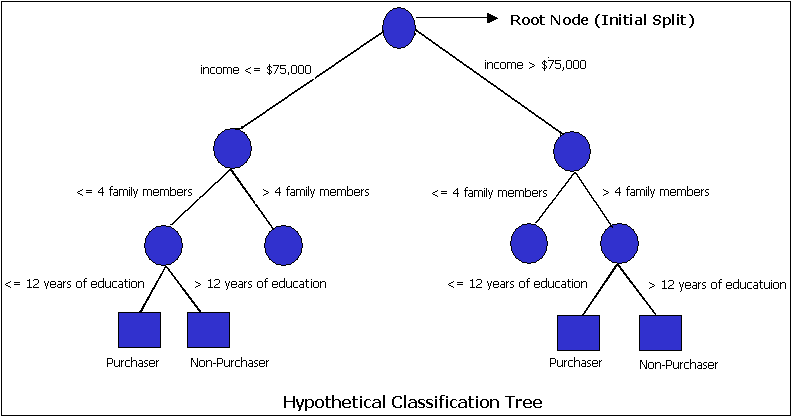
Classification Tree | solver
PDF CS6220: Data Mining Techniques - University of California, Los Angeles measurements, etc.) are accompanied by labels indicating the class of the observations •New data is classified based on the training set •Unsupervised learning (clustering) •The class labels of training data is unknown •Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in ...
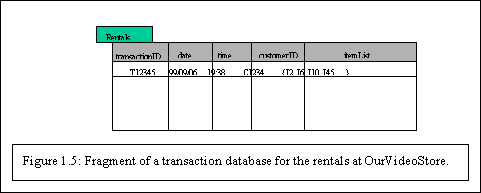
Chapter 1: Introduction to Data Mining
1 The tidy text format | Text Mining with R A tibble is a modern class of data frame within R, available in the dplyr and tibble packages, that has a convenient print method, will not convert strings to factors, and does not use row names. Tibbles are great for use with tidy tools. Notice that this data frame containing text isn’t yet compatible with tidy text analysis, though.

Class labels and the number of samples that appears in "10 ...
Data mining — Class label field - IBM The class label field is also called target field. The class label field contains the class labels of the classes to which the records in the source data were attributed during the historical classification. To identify customers who have allowed their insurance to lapse, you can specify the data fields that are shown in the following table:
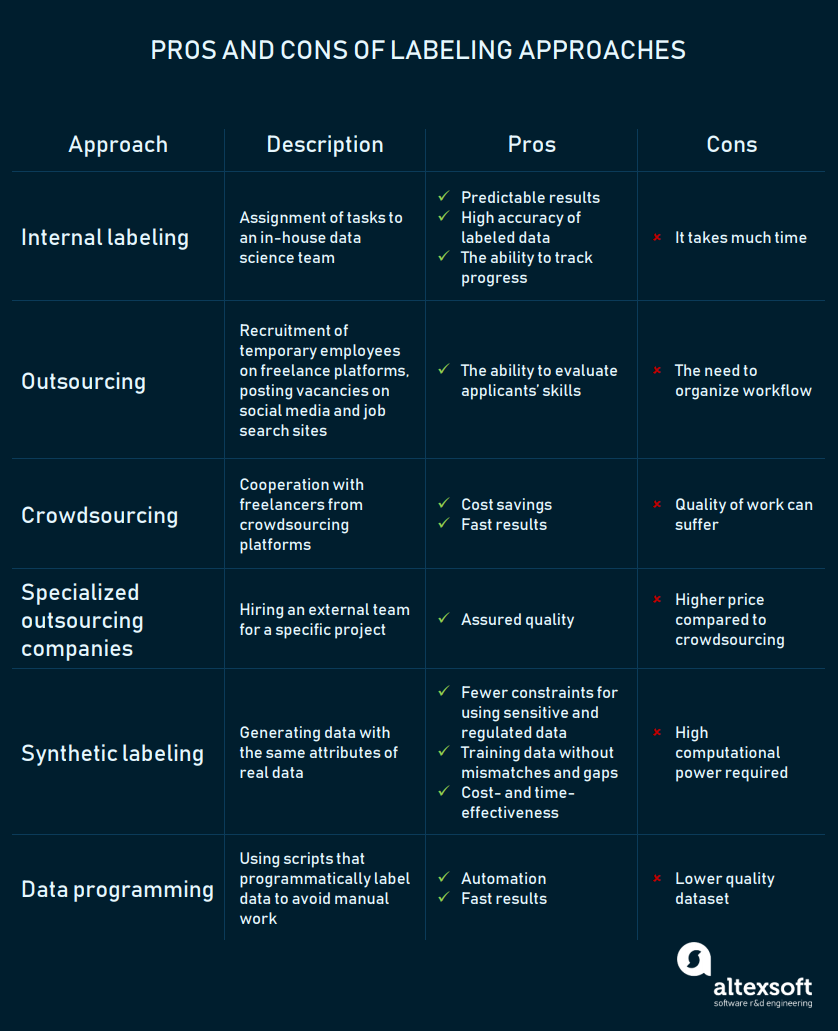
How to Label Data for Machine Learning: Process and Tools ...
Classification and Predication in Data Mining - Javatpoint Classification is to identify the category or the class label of a new observation. First, a set of data is used as training data. The set of input data and the corresponding outputs are given to the algorithm. So, the training data set includes the input data and their associated class labels.

Kind Of Patterns In Data Mining - Notesformsc
Data mining - Class label field The class label field is also called target field. The class label field contains the class labels of the classes to which the records in the source data were attributed during the historical classification. To identify customers who have allowed their insurance to lapse, you can specify the data fields that are shown in the following table:

Decision Tree Classifier
In data mining what is a class label..? please give an example Basically a class label (in classification) can be compared to a response variable (in regression): a value we want to predict in terms of other (independent) variables. Difference is that a class labels is usually a discrete/Categorcial variable (eg-Yes-No, 0-1, etc.), whereas a response variable is normally a continuous/real-number variable.

Decision Tree Algorithm Examples in Data Mining
Draw On Maps and Make Them Easily Use your imagination and our tools to draw routes, trails, and boundaries that help you understand your data better. Analyze your map and discover insights. Filter and visualize your data to identify research trends, data insights, and business opportunities. Share your maps with anyone, securely
![PDF] Analysis of Medical Treatments Using Data Mining ...](https://d3i71xaburhd42.cloudfront.net/da2bee9182872f63fc26746cab29c17dc1f6b5a6/2-Figure1-1.png)
PDF] Analysis of Medical Treatments Using Data Mining ...
Basic Concept of Classification (Data Mining) - GeeksforGeeks It has been constructed to predict class labels (Example: Label - "Yes" or "No" for the approval of some event). Classifiers can be categorized into two major types: Discriminative: It is a very basic classifier and determines just one class for each row of data.

Classification 1. Classification vs. Prediction ...
Data Mining Techniques - GeeksforGeeks The determined model depends on the investigation of a set of training data information (i.e. data objects whose class label is known). The derived model may be represented in various forms, such as classification (if - then) rules, decision trees, and neural networks. Data Mining has a different type of classifier: Decision Tree

Data Science Workflow: Overview and Challenges | Data science ...
Data mining algorithms: Classification - CCSU Step 1: Using a learning algorithm to extract rules from (create a model of) the training data. The training data are preclassified examples (class label is known for each example). Step 2: Evaluate the rules on test data. training sample (2/3) and test sample (1/3). Step 3: Apply the rules to (classify) new data (examples with unknown class
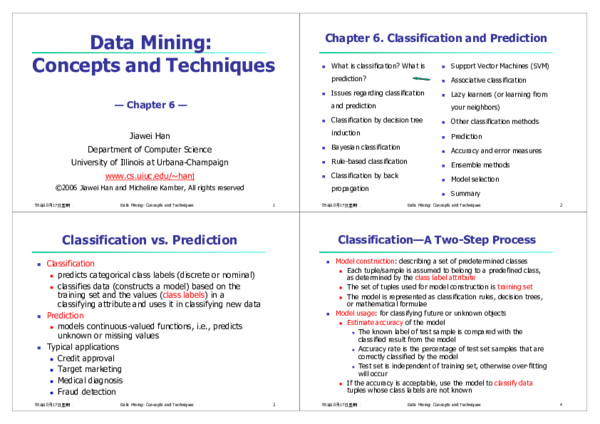
PDF) Data mining: concepts and techniques | Mayuri Kulkarni ...
Data Mining - (Class|Category|Label) Target - Datacadamia Data-Science - Cheatsheet (Class|Category|Label) Target (Classifier|Classification Function) Clustering (Function|Model) Coin Flipping (Prediction|Recommender System) - Collaborative filtering Competitions (Kaggle and others) Confidence Interval Statistics - (Confidence|likelihood) (Prediction probabilities|Probability classification)
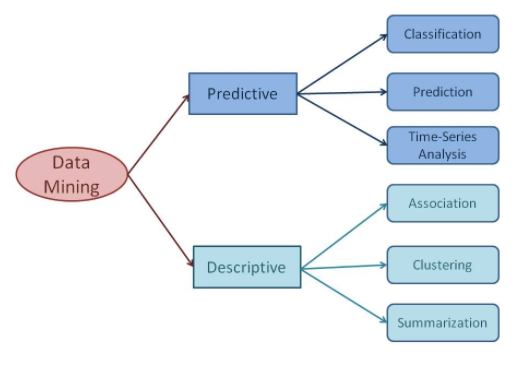
Classification in Data Mining - E2MATRIX RESEARCH LAB

Data Mining Cheat Sheet by HockeyPlay21 - Download free from ...

Classification techniques in data mining

Data Mining Examples and Data Mining Techniques | Learntek

Data Mining:Concepts and Techniques, Chapter 8 ...
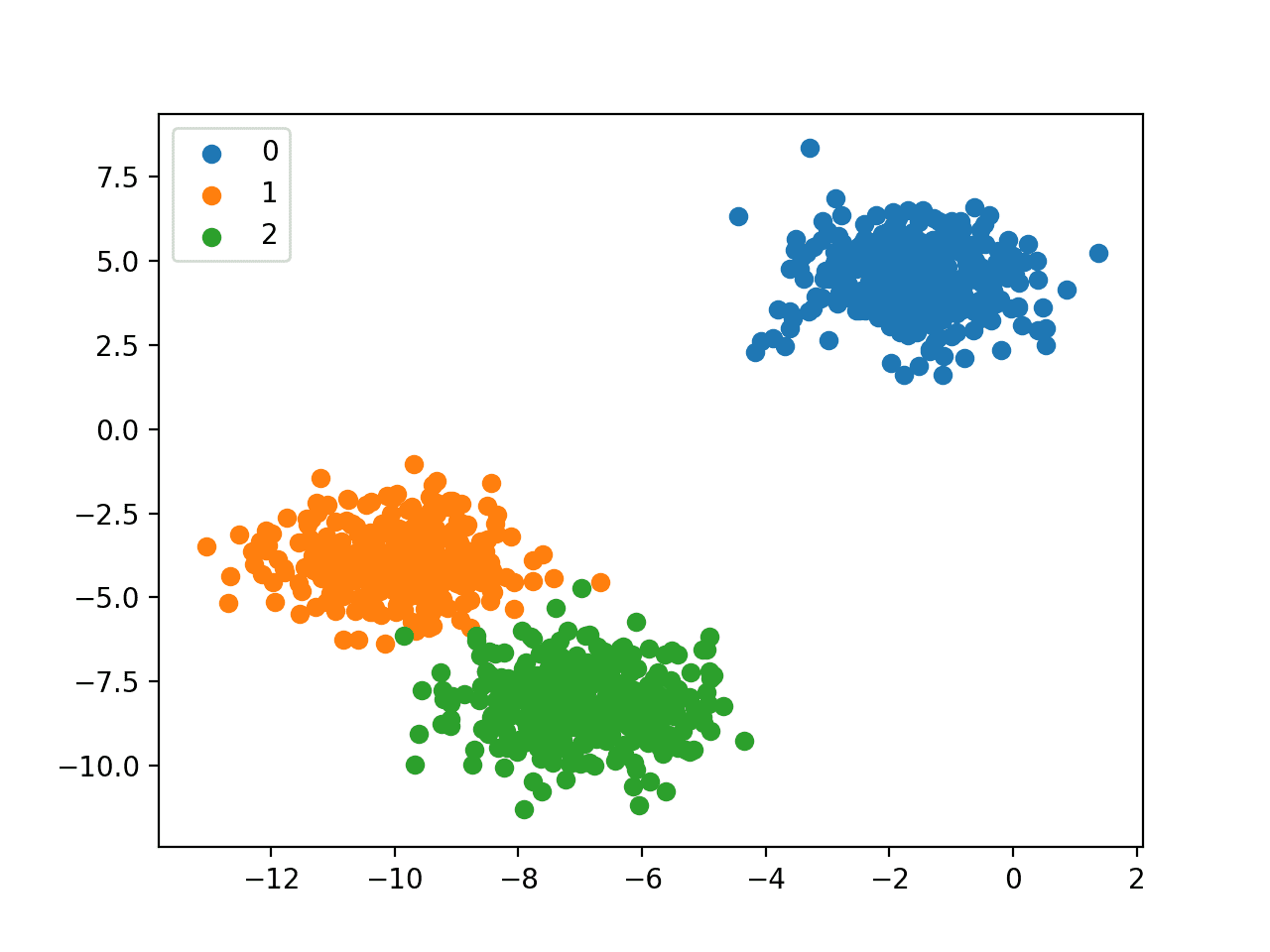
4 Types of Classification Tasks in Machine Learning
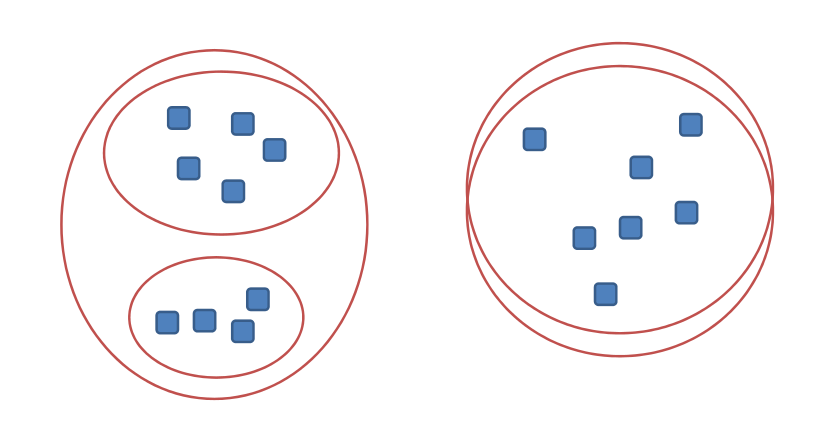
Unsupervised Learning and Data Clustering | by Sanatan Mishra ...

Data Mining: Classification and Prediction - ppt download
Orange Data Mining - Import Documents
![What Is Data Labelling and How to Do It Efficiently [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60d9ab454dc7ad70f8c5d860_supervised-learning-vs-unsupervised-learning.png)
What Is Data Labelling and How to Do It Efficiently [2022]

Data Mining Techniques: Algorithm, Methods & Top Data Mining ...
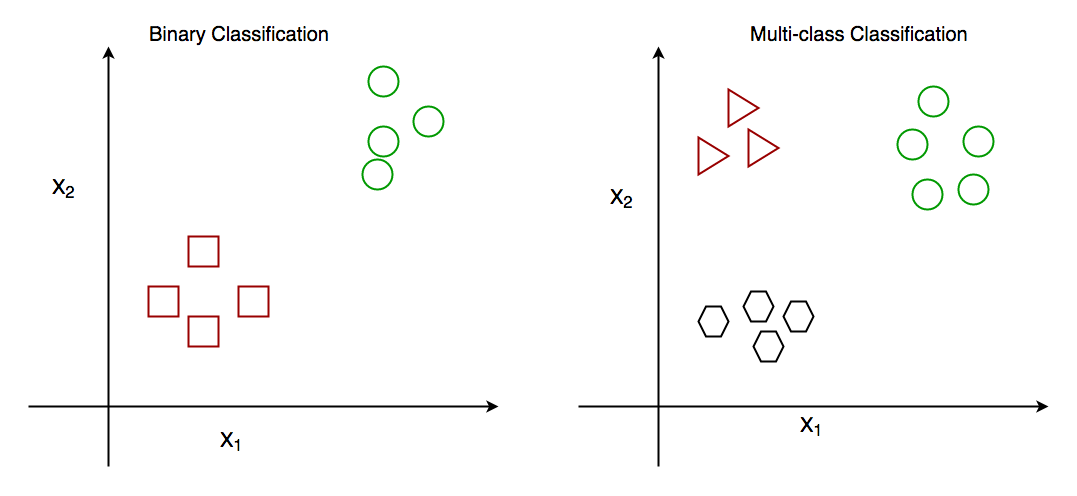
ML | Classification vs Clustering - GeeksforGeeks
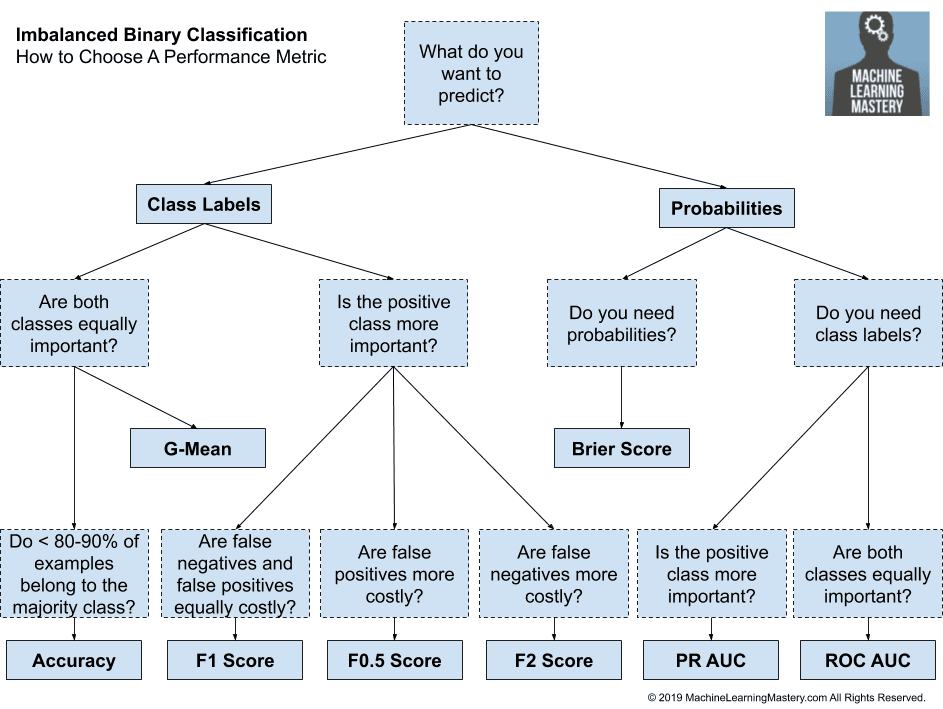
Tour of Evaluation Metrics for Imbalanced Classification
Researchon Classification Techniques in Data Mining
Solved] A summary covering the following topic:. Why ...

2.1 Data Mining-classification Basic concepts
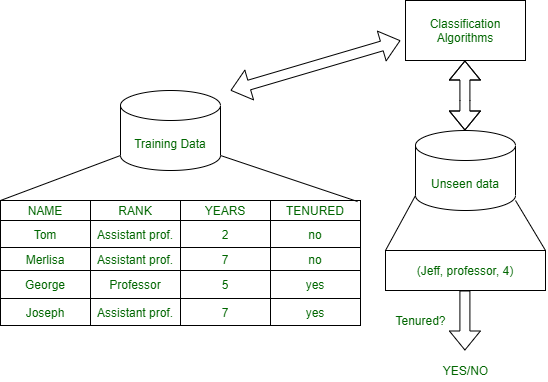
Basic Concept of Classification (Data Mining) - GeeksforGeeks

CS6220: Data Mining Techniques - ppt download

2.1 Data Mining-classification Basic concepts

Dominant class label prediction method. | Download Scientific ...

Training Tuples - an overview | ScienceDirect Topics
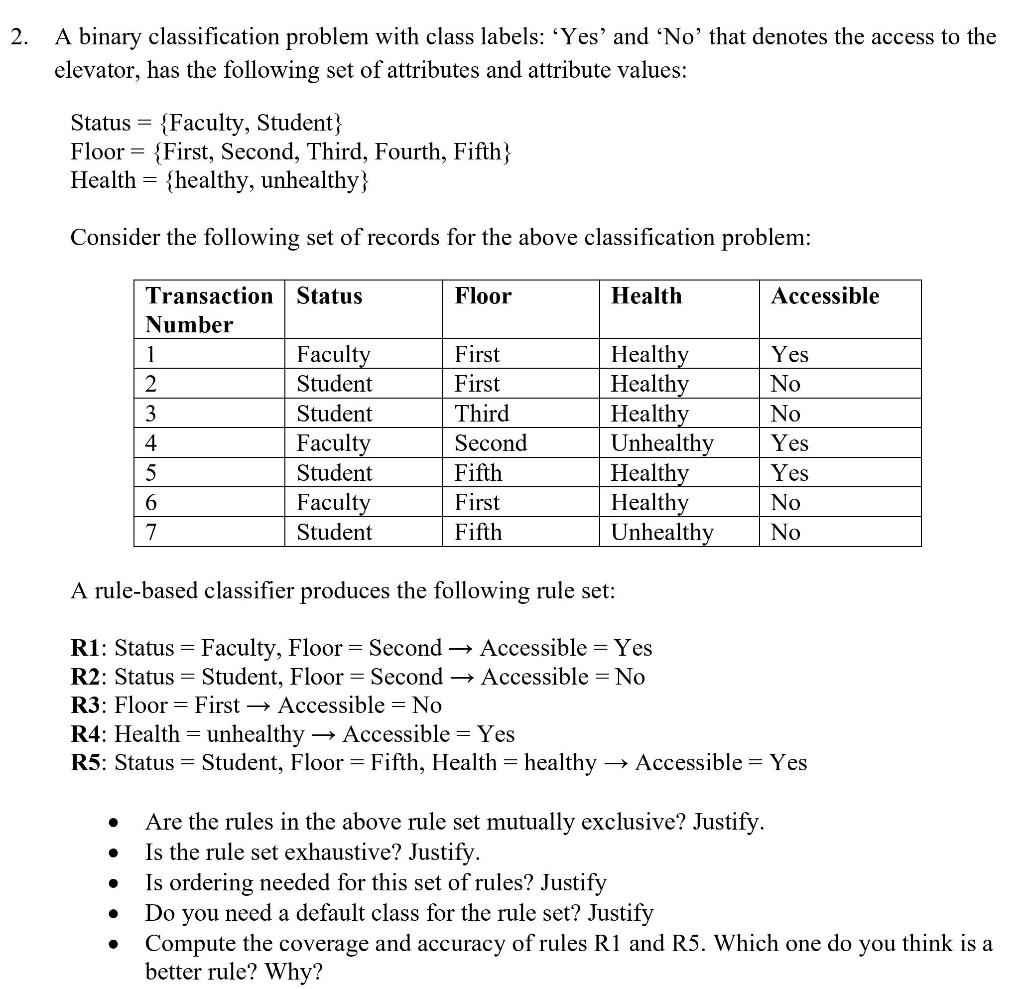
Solved Subject:- Data mining Solve whatever is asked in ...

Lecture Notes for Chapter 4 Introduction to Data Mining - ppt ...

Classification 1. Classification vs. Prediction ...

2.1 Classification and Linear Discriminants (Data Mining and ...

Orange Data Mining - Workflows

Decision Tree Algorithm Examples in Data Mining

2.1 Data Mining-classification Basic concepts
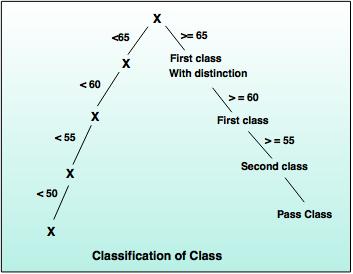
Classification in Data Mining
Classification and Predication in Data Mining - Javatpoint
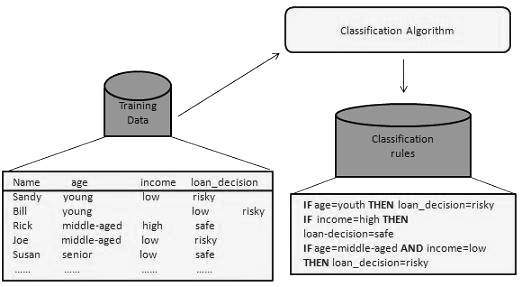
Data Mining - Classification & Prediction
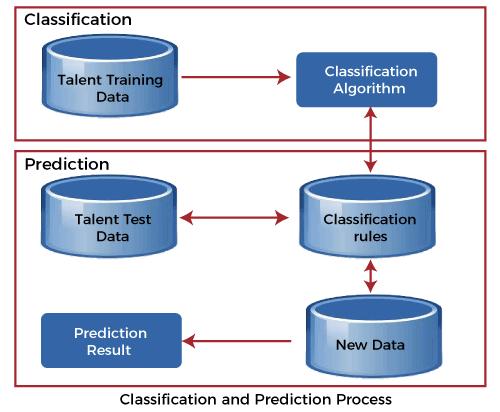
Classification and Predication in Data Mining - Javatpoint

Data Mining Classification Simplified: Steps & 6 Best Classifiers
Post a Comment for "45 class labels in data mining"